Para hacer nuestros modelos de machine learning menos vulnerables y más resilientes ante ataques adversarios, podemos concebir su diseño desde diferentes perspectivas. En este artículo te lo explico.
El investigador italiano Battista Biggio plantea dos modelos conceptuales de defensa: reactiva y proactiva.
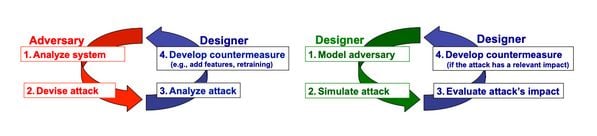
En el caso número uno (defensa reactiva), el cibercriminal analiza nuestro sistema (que se encuentra en producción) y luego realiza un ataque. Cuando nos damos cuenta, reaccionamos desarrollando una medida para mitigarlo.
En el caso #2 (defensa proactiva), nos metemos en los zapatos del cibercriminal. Simulamos un ataque, lo evaluamos y desarrollamos medidas preventivas antes de lanzar nuestro modelo de machine learning a producción. De esa forma, nos anticipamos al acontecimiento antes de que ocurra.
A continuación te doy 3 tips inspirados en la defensa proactiva que te ayudarán a mejorar la seguridad de tus modelos de machine learning:
- Conoce a tu adversario
- Sé proactivo
- Protégete
1. Analiza a tu adversario:
“Si conoces al enemigo y te conoces a ti mismo, no debes temer el resultado de cien batallas”, Sun Tzu.
¡Debemos conocer a nuestro adversario! Y la mejor forma de hacerlo es pensar cómo él. Pensar como él consiste en definir su meta, anticipar el conocimiento que pueda tener de nuestro modelo y la capacidad para manipularlo.
- Meta: la meta del adversario consiste en atacar al menos uno de los pilares fundamentales de la seguridad de la información (conocidos como CIA triad), como se ve en la siguiente imagen:
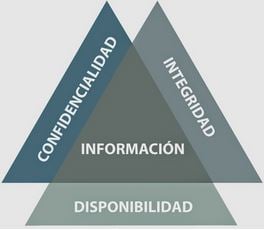
- Integridad: el adversario busca que el modelo de machine learning realice mal la clasificación (falsos positivos o falsos negativos), sin comprometer la disponibilidad del modelo.
- Disponibilidad: el adversario, además de buscar que el modelo de machine learning realice mal la clasificación, también busca que el sistema colapse; es decir, realiza un ataque de denegación de servicios (DDos) para bloquear el acceso a los usuarios legítimos.
- Confidencialidad/privacidad: el adversario busca realizar ataques al modelo que revelen o puedan inferir datos sensibles de los usuarios o del sistema.
Conocimiento del modelo:
Una vez identificamos la meta, en esta fase nos enfocamos en responder la siguiente pregunta: ¿qué conoce el adversario de nuestro modelo? El adversario puede tener conocimiento de tres elementos:
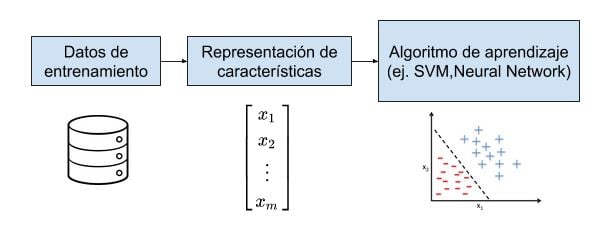
Si el adversario tiene total conocimiento de los datos de entrenamiento, de la representación de las características de los datos y del algoritmo de aprendizaje que usamos, puede realizar un ataque de caja blanca o white box contra nuestro modelo, siendo este el peor caso para nosotros.
En caso de que el adversario no conozca uno de estos elementos, puede realizar un ataque de caja gris (conocimiento limitado) o gray box.
Finalmente, si no tiene conocimiento de ninguno de estos tres elementos, podría realizar un ataque de caja negra o black box, que sería el mejor caso para nosotros, ya que realizar un ataque black box no es para nada trivial y limita a nuestro adversario.
Siguiendo el principio de Kerckhoff, cuando se trata de machine learning versus un adversario, no debemos asumir que el adversario es débil. Es una buena práctica suponer que al menos el adversario conoce en la mayoría de los casos un poco sobre la representación de las características de los datos y el algoritmo de aprendizaje (gray box). En este punto es importante estudiar el peor y el mejor caso para determinar qué tan lejos están uno del otro.
Capacidad del adversario:
Luego de identificar el conocimiento que tiene el adversario sobre nuestro modelo, debemos preguntarnos lo siguiente: ¿qué capacidad tiene el adversario para alterar el modelo? El adversario podría intervenir en dos fases principales: la fase de entrenamiento del modelo y la fase de testing o evaluación (donde realiza la clasificación).
Si el adversario tiene acceso y conocimiento de los datos de entrenamiento, puede modificarlos para causar una falla en el clasificador. Esto es conocido como ataque de envenenamiento o poisoning attacks. Generalmente ocurre cuando el adversario conoce los 3 elementos de nuestro modelo (white box).
Para las alteraciones en la fase de evaluación, generalmente el modelo ya se encuentra entrenado y en producción. El adversario puede manipular los datos que recibe por parámetro del modelo, hasta que realice mal una clasificación. Esto es conocido como ataques de evasión o Evasion attacks.
2. Sé proactivo
Una vez conocemos a nuestro adversario, el siguiente paso es tratar de anticipar sus movimientos. ¿Cuál es el ataque que podría usar contra nuestro modelo?
En este punto debemos simular y observar qué tan crítico es este tipo de ataque. En el caso de los ataques de envenenamiento y evasión, es un poco más complejo simularlos, ya que se debe plantear como un problema de optimización. A través de un algoritmo (como por ejemplo descenso de gradiente), introducimos pequeñas perturbaciones hasta lograr engañar al modelo.
3. Protégete
El último tip consiste en proteger nuestro modelo con respecto a futuros ataques. Barreno define el término Secure Learning como la habilidad de un modelo de machine learning de tener un buen desempeño incluso en condiciones adversas, (es decir cuando un adversario intenta realizar un ataque en contra de nuestro modelo). Este es finalmente nuestro propósito.
El método de protección va a depender del tipo de ataque.
Ataques de evasión
“Ningún mar en calma hizo experto a un marinero”, Franklin D. Roosevelt.
Para el caso de los ataques de evasión, se puede utilizar una estrategia llamada Adversarial Training. Esta técnica consiste en generar datos adversarios que el modelo no pueda clasificar o que falle al clasificarlos (falsos negativos o falsos positivos).
Estos datos se mezclan junto con los datos de entrenamiento y se reentrena el modelo para que sea menos vulnerable ante estos ataques. Sin embargo, esta es una estrategia heurística (basada más en la experiencia), pero con buenos resultados en la mayoría de los casos.
En mi proyecto de grado para obtener el título de ingeniero de sistemas, propuse una estrategia de este tipo. Bajo la supervisión del profesor experto en ciencia de datos y ciberseguridad Christian Urcuqui, planteamos una estrategia de reinforcement Learning en un modelo de machine learning que detectara Android Malware a través de 10 características de red.
Esta estrategia (whitebox) consistía en analizar como un juego la lucha entre el adversario y el modelo. El algoritmo de Reinforcement Learning se encargaba de perturbar los datos hasta lograr que el modelo fallara. Después se mezclaban con los datos originales y se reentrenaba el modelo para volverlo menos vulnerable. Finalmente se logró que el modelo clasificara de manera correcta aproximadamente al menos 71% de los datos adversarios.
Ataques de envenenamiento:
Para el caso de los ataques de envenenamiento, es importante que el acceso al conjunto de datos que se tiene para realizar el entrenamiento del modelo sea limitado a un número reducido de personas para evitar que puedan inyectar estos datos.
Finalmente cabe resaltar que el sistema donde esté en producción nuestro modelo de machine learning también debe estar seguro, siempre velando por proteger los pilares fundamentales de la seguridad informática.

Comparte

Tendencias y retos de la transformación Digital en el sector retail

Robotic Process Automation: conoce los beneficios para empresas

5 pasos para lograr una Transformación Digital exitosa
