

por Nicolás Archila Gómez, el 23 de junio de 2022

En esta tercera parte explicaremos la manera en que se puede incorporar el paralelismo en la concurrencia y cubriremos algunos de los errores comunes al momento de trabajar con hilos. Puedes encontrar aquí la parte 1 y la parte 2 de esta serie de artículos.
¿Cómo incorporar paralelismo en la concurrencia?
Ahora vamos a hablar un poco de ForkJoinPool para ver como se puede potenciar la ejecución de concurrencia integrando paralelismo. Fork/join framework fue presentado en java 7. Forks de manera recursiva rompe la tarea del hilo en pequeñas subtareas hasta que sean tan simples que se puedan ejecutar de manera asincrónica y después de ello, une los resultados de todas las subtareas en un solo resultado. En caso de que una tarea esté en un método void que no tiene un retorno, el framework simplemente espera hasta que se ejecuten todas las subtareas para finalizar dicho proceso.
Para proveer paralelismo en el caso que acabamos de mencionar y aprovechar toda la potencia del framework, podemos usar un pool de hilos que manejan hilos en batch del tipo ForkJoinWorkerThread. ForkJoinPool es el corazón del framework que estamos teniendo en consideración, este es una implementación del ExecutorService que maneja los hilos en batch o hilos trabajadores y nos provee herramientas para obtener información del estado y el rendimiento del pool de hilos con el que estamos trabajando. Es importante aclarar que ForkJoinPool no crea un hilo para cada subtarea, por el contrario, cada hilo en el pool tiene una cola que almacena las subtareas y las va ejecutando.
ForkJoinPool se apoya en el uso del algoritmo work-stealing. Este es una estrategia programada para trabajar programas multihilo y consiste en que cada procesador o core tiene una cola de ítems de trabajo para ser ejecutarlos de manera secuencial; pero, en el curso de la ejecución un ítem puede tener más ítems de trabajo que pueden ser ejecutados en paralelo colocándolos en las colas que están dispuestas para ser trabajadas por los procesadores. Cuando un procesador termina el trabajo de su cola, toma otros ítems de otras colas y los procesa. En el caso de ForkJoinPool, cada procesador o core es un hilo, también es importante tener presente el pool de hilos con los que va a trabajar el framework, puesto que el procesador tiene un número de cores para procesar todas las operaciones y podríamos causar bloqueos en el mismo. A continuación, vamos a mostrar un ejemplo para entender cómo trabaja este esquema y vamos a usar ForkJoinTask para trabajar las tareas del proceso en un pool de hilos. El ejemplo es tomado de baeldung.
En la siguiente imagen se puede ver como se recibe un String y se subdivide hasta que quede un String muy simple que se procesa para convertirlo en mayúscula.
package com.thread.demo; import java.util.ArrayList; import java.util.List; import java.util.concurrent.ForkJoinTask; import java.util.concurrent.RecursiveAction; import java.util.logging.Logger; public class CustomRecursiveAction extends RecursiveAction{ private String workload = ""; private static final int THRESHOLD = 4; private static Logger logger = Logger.getAnonymousLogger(); public CustomRecursiveAction(String workload) { this.workload = workload; } @Override protected void compute() { if (workload.length() > THRESHOLD) { ForkJoinTask.invokeAll(createSubtasks()); } else { processing(workload); } } private List<CustomRecursiveAction> createSubtasks() { List<CustomRecursiveAction> subtasks = new ArrayList<>(); String partOne = workload.substring(0, workload.length() / 2); String partTwo = workload.substring(workload.length() / 2, workload.length()); subtasks.add(new CustomRecursiveAction(partOne)); subtasks.add(new CustomRecursiveAction(partTwo)); return subtasks; } private void processing(String work) { String result = work.toUpperCase(); logger.info("This result - (" + result + ") - was processed by " + Thread.currentThread().getName()); } } |
En el siguiente fragmento de código, se ejecuta en el método principal, el método que va a iniciar el trabajo de procesamiento con ForkJoinTask enviando un String para iniciar:
public static void main(String[] args) { CustomRecursiveAction forkJoinExample = new CustomRecursiveAction("NicolasRicardoArchilaGomez"); forkJoinExample.compute(); } |
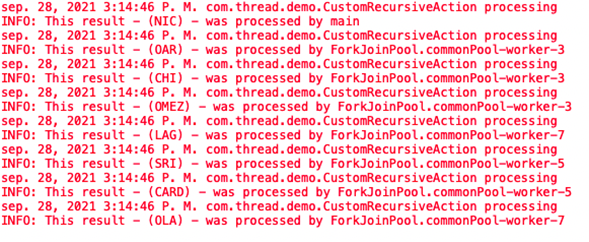
Finalmente, se puede observar en la siguiente imagen cómo el String fue dividido y procesado por diferentes hilos hasta completar el String, para este caso no se retorna nada, por lo que como explicamos anteriormente, el procesamiento culmina cuando cada subtarea termina de ser ejecutada; en caso de que haya un retorno, el proceso al final une todos los resultados y hace la entrega final. Si deseas saber un poco más al respecto puedes ir a baeldung, de dónde fue tomado este ejemplo.
Errores comunes al momento de trabajar con hilos
Luego de hablar sobre los hilos, el potencial que tienen y la manera de manejarlos, vamos a hablar un poco de algunos errores conocidos que se deben tener en cuenta cuando trabajamos con ellos.
Starvation – lived lock:
Este es un error que maneja el sistema operativo, el cual asigna prioridad a los procesos para su respectiva ejecución y el problema que puede suceder con respecto a esto es que haya procesos con baja prioridad que nunca se ejecuten, para lo cual se genera una estrategia aging que se basa en subir cada cierto tiempo un punto de prioridad a esas tareas que podrían no ejecutarse nunca y de esta manera llegará un momento en el tiempo en el que se volverán prioritarias y podrán se ejecutadas.
DeadLock – Circuit wait:
Es otro tipo de error muy común cuando se manejan los hilos y consiste en que si un thread1 consume un método A y un thread2 consume un método B, ambos bloquean el método por sincronización; pero, thread1 debe consumir el método B para soltar el método A y el thread2 debe consumir el método A para soltar el método B. Como se puede observar en este caso, se genera un bloqueo infinito y debemos estar muy pendientes al momento de crear hilos para que no nos ocurra esto y cause un incidente grave en nuestra aplicación.
Una vez que aprendimos que es un hilo, como trabaja, algunos ejemplos directos con java y algunas buenas prácticas referentes al manejo de los mismos, sería muy relevante que puedan ver un ejemplo en Spring Boot para lo cuál recomendamos ir a la siguiente URL https://www.adictosaltrabajo.com/2011/12/27/spring-asynchronous/
CONCLUSIÓN
En esta serie de tres artículos aprendimos un poco sobre qué es un hilo y por qué es tan necesario en ambientes multitarea, cómo podemos incrementar o mantener el rendimiento de las aplicaciones con un buen manejo de hilos, así como también, los puntos que se deben tener en cuenta para no cometer errores que afecten nuestra aplicación. Este texto contiene una fundamentación sobre los hilos, que es muy importante conocer para saber cómo trabajan, en qué contexto usarlos, cuáles pueden ser los posibles errores cuando algo falle en nuestra implementación y a medida que se avanza en la lectura se van incorporando estrategias de manejo de hilos más controladas y con menor esfuerzo. Se recomienda usar librerías y plugins que nos provee java y Spring Boot para sacar el mayor potencial al manejo de hilos y seguir profundizando, para lo cuál puedes ingresar a la página oficial de baeldung.
Si quieres ir a un nuevo nivel de conocimiento en términos de concurrencia y su aplicación en ambientes reales te invitamos a conocer sobre los patrones de concurrencia cómo: Object Active, Balking, Reactor y Thread Pool.




