

por Ricardo Caicedo, el 21 de mayo de 2016

Hoy hablaremos de un software para el manejo de control de versiones denominado Git. Para empezar, conoce los conceptos básicos y sus beneficios.
En tiempos prehistóricos, cuando los expertos desarrollaban código para algún proyecto de software no guardaban lo que tenían adelantado, por ende, si el equipo se apagaba, perdían todo. El hecho de querer recuperar el código viejo resultaba muy difícil y si dos personas trabajaban en un mismo código, era una tarea casi imposible.
Todo esto fue evolucionando hasta que en algún momento llegaron los sistemas de control de versiones. Como su nombre lo indica, permiten guardar versiones estables del software para posteriores salidas a producción o pruebas.
Aparte tenemos el registro de los cambios realizados por cada uno de los miembros de desarrollo para que al momento de unir estas capas todo pueda fluir y se reduzca el margen de error.
Entre los sistemas más utilizados hasta hace algún tiempo estaban Subversion, SourceSafe, Mercurial, entre otros. En el año 2005 empezó a gestarse una historia bastante interesante con el núcleo de Linux y su sistema de control de versiones descentralizado (DVCS). El proyecto empezó a sufrir cambios en su manejo, y ahí nació Git.
¿Qué es Git?
Es un software para el manejo de control de versiones de nuestro código. Una de las cosas por las cuales los desarrolladores utilizan, por encima de otros sistemas, es por su velocidad. Es ágil y sencillo.
A diferencia de SVN, por ejemplo, Git hace honor a su nacimiento, siendo un sistema de control de versiones distribuido. Así como existe el repositorio central (o remoto) del proyecto, cada desarrollador posee en su equipo lo que se conoce como repositorio local. Esto ayuda de gran manera a tener un control más ordenado, preciso, y además, reduce el porcentaje de error.
Etapas de un archivo en GIT
Empecemos por conocer las etapas importantes que les ocurren a los archivos dentro de un repositorio de Git. Supongamos que tenemos el desarrollo de un proyecto que tiene como principio un carro de compras. Hasta el momento, solo tenemos un módulo que se encarga de publicar productos, pero vemos la necesidad de desarrollar otro para el registro de los usuarios en el sitio.
Con ese fin, iniciamos el desarrollo del módulo hasta el final. Tenemos la necesidad de registrar los cambios que tuvieron los archivos, de crear nuevos, y por qué no, volver a los eliminados. Debemos realizar, entonces, algunos pasos que veremos más adelante; sin embargo, veremos qué ocurre con estos archivos en las distintas fases:
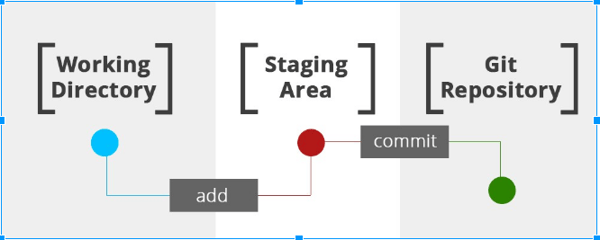
Acá empezamos a manejar tres conceptos nuevos: working directory, staging area y Git repository. Todos los cambios que hemos realizado para el desarrollo del nuevo módulo, actualmente se encuentran en estado “Modificado” y estos están en el working directory.
Una vez le digamos al sistema cuáles archivos o cambios queremos subir al repositorio, estos pasarán a estado “Preparado” y se encontraran en el staging area. Por último, cuando ya estemos seguros y pasemos estos cambios a estado “Confirmado”, ya estarán en nuestro git repository. Al momento de llegar a esta fase final, nuestro repositorio ya poseerá la actualización del módulo de usuarios.
Repositorio en GIT
Hemos hablado de muchas cosas hasta ahora, pero aún no definimos el concepto de repositorio. Un repositorio no es más que un conjunto de archivos puestos en una o varias carpetas para el manejo y la configuración de nuestro proyecto. Para este caso, el repositorio está configurado con Git.
Fases en el repositorio
Como lo mencioné arriba, existen algunos pasos con el fin de lograr completar las fases y tener los estados comentados en el punto anterior. Para entender cómo funcionan estos pasos o comandos veremos nuevos conceptos de Git.
- Add: este método nos permite agregar los cambios realizados, es decir, cambia el estado de nuestros archivos de “Modificado” a “Preparado”, pasa los archivos del working directory al staging area.
- Commit: realiza el cambio de nuestros archivos en estado “Preparado” a “Confirmados”, lo que quiere decir que los deja finalmente en el git repository.
Qué son las ramas y cómo funcionan
Ya vimos las fases por las que pasan nuestros archivos y los métodos que nos permiten hacer dichos pasos, todo esto dentro de un repositorio local. Ahora, conozcamos un nuevo concepto llamado 'ramas': las líneas de desarrollo únicas que se encuentran dentro del repositorio y nos ayudan a tener mayor control. De hecho, un repositorio debe tener al menos una rama. Por convención, la rama principal es denominada “máster”.
Traduciendo un poco lo anterior y tomando el mismo ejemplo del sitio con un carro de compras, para el desarrollo del módulo de usuarios, deberíamos trabajar de una forma en la que no dañemos el que tenemos funcionando de forma correcta, en este caso, el módulo de productos. Por ello, se creó el concepto de ramas.
Para el supuesto, todo nuestro desarrollo se encuentra en la rama máster, y al iniciar el nuevo desarrollo, lo haremos en una rama que llamaremos “usuarios”. De esta forma, si algo llegara a salir mal, saldrá mal en la rama “usuarios” y no en la rama máster. Esto garantizará la integridad de nuestro código.
Una vez finalizado el desarrollo del módulo y después de haber verificado que se encuentre correctamente diseñado y probado, podremos unir nuestro código de la rama de usuarios al código de la rama máster.
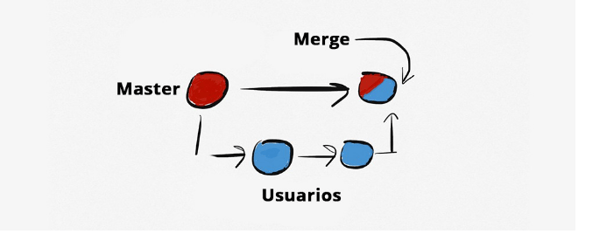
Así, hemos actualizado ya nuestro proyecto. Esto lo permite hacer Git de una manera muy sencilla e íntegra. Desde un punto de vista gráfico lo podemos observar en la siguiente imagen:
Cómo aplicar GIT en un proyecto
Ahora pasemos a la parte divertida. Vamos a ver cómo toda esta teoría se empieza a concretar en la vida real.
Merge
Acá nos encontramos con un nuevo y popular concepto dentro del entorno git. En la imagen podremos ver una explicación gráfica que nos resume lo que es un Merge: la unión de una rama con otra, sencillamente eso.
Estos conceptos son utilizados en nuestro día a día en el manejo de git, pero ahora pasemos a la parte divertida. Vamos a ver cómo toda esta teoría se empieza a concretar en la vida real.
Instalación de GIT
Para poder pasar a la diversión, debemos tener instalado Git en nuestros equipos. Quienes deseen realizar la instalación haciendo uso de un entorno gráfico (cualquier plataforma) pueden descargarlo en este enlace: https://git-scm.com/downloads
Los más geeks, podemos instalar Git desde nuestra línea de comandos desde un Mac, haciendo a través del siguiente comando (recuerda tener instalado Homebrew): $ brew install git. Si te encuentras en Linux, puedes utilizar los siguientes comandos: para fedora,$ yum install git-core; para Debian o Ubuntu, $ apt-get install git.
Una vez realizada la instalación, pasarás a formar parte de un grupo de gente interesante y cool.
Creando el primer repositorio
 Vamos a crear nuestro primer repositorio. En nuestro caso, que somos muy geeks, todos los pasos que realizaremos a continuación, serán mediante nuestra consola de comandos. Sea la plataforma que sea (Windows, Linux o MacOs) estas líneas serán transparentes para ti.
Vamos a crear nuestro primer repositorio. En nuestro caso, que somos muy geeks, todos los pasos que realizaremos a continuación, serán mediante nuestra consola de comandos. Sea la plataforma que sea (Windows, Linux o MacOs) estas líneas serán transparentes para ti.
Lo primero que realizaremos es entrar mediante nuestra consola de comandos a la carpeta en la que queremos crear nuestro repositorio. La llamaremos example, y pondremos el siguiente comando: Git init.
Como podremos ver, luego de ejecutarlos, la línea de comandos nos anuncia que hemos inicializado un nuevo repositorio. Cuando creamos un nuevo repositorio, nos pone en la rama máster, como la principal del proyecto.
Si verificamos lo que tenemos dentro de la carpeta del proyecto, encontraremos una carpeta Git, en donde se encuentra toda la configuración y el almacenamiento de nuestro repositorio.
Esta es administrada por Git para nuestro repositorio. En lo posible, trataremos de no manipularla ni mucho menos, borrarla, ya que perderíamos todo el histórico de nuestro repositorio. Para finalizar este primer episodio de Git, vamos a poner en práctica dos de los conceptos mencionados: add y commit.
Para esto crearemos un nuevo archivo vacío en la carpeta, el cual llamaremos readme.md. Tú puedes utilizar este mismo o algún otro que quieras; la finalidad es la misma. Luego por línea de comandos desde la carpeta del repositorio ejecutamos el siguiente comando. Este nos permitirá conocer el estado de los archivos de nuestro repositorio: Git status.
Podemos ver que Git nos dice que existen archivos que se encuentran en estado Untracked; es decir, que no les hacemos versionamiento dentro del repositorio, ya que son nuevos.
Este estado es el que llamamos Modificado. Para pasarlos al Staging Area, debemos agregarlos con el comando add.
Al momento de realizar add, es importante que sepamos que lo podemos hacer masivo o detallado dependiendo de nuestras necesidades. En este ejemplo ,vamos a realizar un add masivo, pues solo tenemos un archivo por subir, así que ejecutamos el comandogit add -A. Seguidamente ejecutamos nuevamente el siguiente comando para conocer el estado de nuestro repositorio: Git status.
Acá podemos ver que nuestro archivo se ha vuelto de color verde, lo que nos indica que se encuentra en estado Preparadodentro del Staging area; está listo para ser confirmado en nuestro repositorio y para tal fin colocaremos el siguiente comando: git commit -m “Mi primer commit :)”
Con el comando commit, pasamos nuestro archivo a estado Confirmado y se encuentra listo dentro de la rama máster en nuestro Git repository. Lo que quiere decir que, si alguna persona quiere clonar (concepto que manejaremos más adelante) nuestro repositorio para realizar otros desarrollos, en el momento que lo haga va a tener el archivo readme.md dentro de los archivos de la rama.
El comando -m nos permite colocar un mensaje al commit, de tal forma que podamos identificar más fácilmente qué hacemos en cada confirmación de nuestro código. También hay que resaltar que por convención nuestro primer commit debe tener el título de “primer commit” y tratar de que solo tenga un archivo. En este caso, ponemos como ejemplo el archivo readme.md, que idealmente debe tener en su interior las características del proyecto que estamos realizando.
Con esto damos por finalizado el primer capítulo de la serie. Tratamos siempre de ser específicos en lo que explicamos. Si en algún momento se presentan dudas, con gusto dejamos a disposición nuestro formulario para comentarios.
Lee el especial completo:
- Comandos básicos de GIT
- Cómo crear un repositorio remoto de GIT
- Qué es una rama de GIT y cómo crearlas
- Cómo aplicar Git Stash y Git Cherry-pick
- Flujos de trabajo en GIT




